Cartes Choroplètes avec Python
Créez une carte choroplèthe avec geoviews et geopandas.
Les cartes choroplèthes sont un excellent moyen de donner du sens à un échantillon de données géographique.
Comme les heat maps (cartes de chaleur), elles montrent les variations locales d'une mesure, comme celle de la densité de population. Mais contrairement aux heat maps qui moyennent les mesures dans des bins arbitraires, les cartes choroplèthes le font suivant des frontières prédéfinies (états, villes, ou autres).
Dans cet article, vous utiliserez les toutes dernières librairies de visualisation de python pour dessiner des cartes choroplèthes. Vous apprendrez à :
- installer holoviz, geopandas, et geoviews à l'intérieur d'un environnement conda,
- créer vos premières cartes du monde,
- trouver les définitions des frontières géographiques pour pouvoir faire des cartes,
- connecter votre propre échantillon de données aux frontières géographiques pour cartographier ce que vous voudrez.
Installation
D'abord, Installez Anaconda.
Ensuite, créez un nouvel environnement conda pour cet exercice, appelé holoviz :
conda create -n holoviz
Activez-le
conda activate holoviz
Maintenant, vous pouvez installer holoviz, un ensemble de outils de haut niveau pour la visualisation en python :
conda install -c pyviz holoviz
Nous devons en plus installer geopandas et geoviews, qui sont des librairies additionnelles pour l'analyse et la visualisation des données géographiques :
conda install geopandas geoviews
Enfin, voici les fichiers que nous utiliserons dans ce tutoriel (jupyter notebook, échantillon de données), au cas où vous en ayez besoin.
graphiques interactifs dans le navigateur : cela nécessite JavaScript.
Nous venons en fait d'installer un grand nombre de packages python, qui seront (ou pas) nécessaires pour l'analyse et la visualisation de données géographiques.
Voici une description simplifiée des dépendances entre certains de ces packages :
- geoviews : visualisation géographique
Cela peut sembler un peu compliqué, et ça l'est!
Actuellement, à la fin de l'année 2019, le paysage de la visualisation en python est en profonde mutation, et il peut être difficile de choisir les bons outils. Personnellement, voici ce que je recherche :
- une syntaxe compacte : Je veux pouvoir créer des graphiques sans perdre de temps à écrire du code, pour une compréhension rapide de mes données.
- graphiques interactifs dans le navigateur : cela nécessite JavaScript.
- big data : en d'autres termes, pouvoir afficher beaucoup de données sans tuer le navigateur client.
- python : je ne veux pas avoir à développer en JavaScript, sauf si vraiment nécessaire.
Formaliser ces quatre points m'a vraiment aidé à choisir mes outils. Par exemple, le point 4 élimine les librairies de visualisation JavaScript telles que D3.js. Je continue de penser que ces librairies sont idéales pour un affichage professionnel et à grande échelle dans le navigateur. Mais D3, par exemple, n'est pas très facile d'accès... J'y ai déjà passé une bonne semaine, et ne suis pas allé bien loin ! Je préfèrerai certainement faire appel à un expert lorsque j'aurai besoin d'un affichage basé sur D3, plutôt que d'apprendre à l'utiliser.
Bokeh, d'un autre côté, permet à l'utilisateur d'utiliser JavaScript tout en codant en python (et ce sans faire appel à D3). C'est donc exactement ce dont j'ai besoin pour le point 2.
Souvent, j'utilise bokeh directement, comme dans Affichez vos données sur une Google Map avec python ou dans Interactive Visualization with Bokeh in a Jupyter Notebook. Mais il faut souvent écrire une douzaine de lignes de code pour obtenir un graphique bokeh.
Holoviews sert d'interface de haut niveau à bokeh ou matplotlib. Il permet de créer des graphiques complexes en deux lignes de code, et répond donc au point 1.
Enfin, quand je souhaite afficher du big data, j'utilise datashader, une librairie qui permet de compresser les données en une image dynamiquement avant de l'envoyer comme graphique bokeh au client. Là encore, bokeh et holoviews sont parfaits.
En juin 2019, le projet holoviz a été lancé. L'équipe de holoviz rassemble les outils dont j'ai besoin, et semble partager mon opinion concernant l'évolution future de la visualisation en python. J'utilise donc maintenant holoviz comme point d'entrée principal pour la visualisation. Si vous souhaitez en savoir plus sur ce projet, vous pouvez vous référer à sa FAQ.
Premières cartes avec geoviews¶
on importe les outils dont nous aurons besoin, et on initialise geoviews :
import geoviews as gv
import geoviews.feature as gf
import xarray as xr
from cartopy import crs
gv.extension('bokeh')


geoviews.feature contient la description géométrique des différentes régions, comme les terres, l'océan, et les frontières des pays. Affichons tout ça :
(gf.land * gf.ocean * gf.borders).opts(
'Feature',
projection=crs.Mercator(),
global_extent=True,
width=500
)
Avec cartopy, nous pouvons facilement changer la projection:
(gf.land * gf.ocean * gf.borders).opts(
'Feature',
projection=crs.NearsidePerspective(central_longitude=0,
central_latitude=45),
global_extent=True,
width=500, height=500
)
Trouver d'autres régions¶
Pour l'instant, nous avons extrait les régions que nous voulions tracer (gf.land, gf.ocean, gf.borders) de geoviews.features. Voyons ce que nous pouvons trouver d'autre dans ce module :
dir(gf)
En fait, pas grand chose. Ces régions ont été prédéfinies pour les cas communs, et sont assez limitées en pratique. Par exemple, les régions statessont restreintes aux États-Unis.
Cartopy, qui est en fait utilisé par geoviews pour obtenir les terres, l'océan, et les frontières, fournit une interface permettant de récupérer des régions de diverses sources, comme Natural Earth.
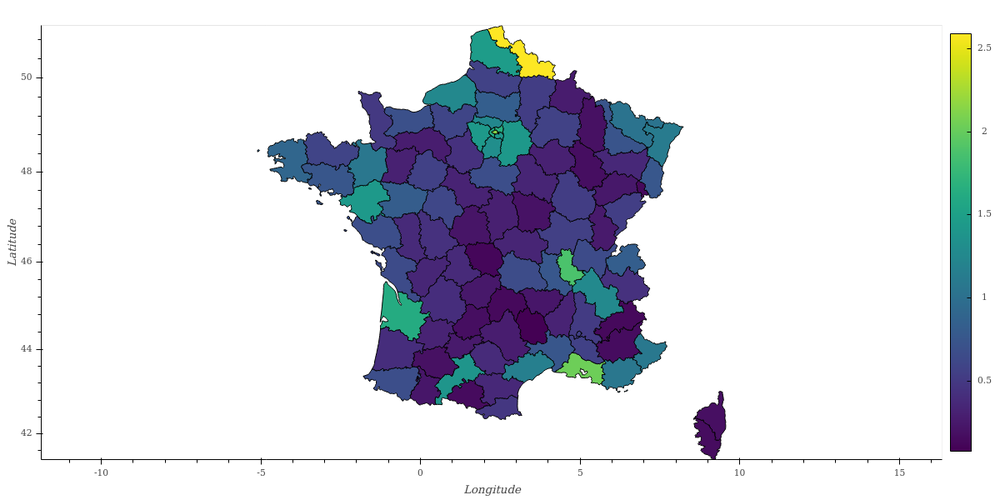
Mais si vous cherchez quelque chose de très spécifique, vous risquez de ne pas le trouver. Par exemple, je n'ai pu trouver de description des départements français pour créer la carte que vous avez vue en tête de cet article.
Dans la section suivante, nous allons voir comment travailler avec n'importe quelle jeu de régions.
Charger un fichier GeoJSON avec pandas¶
Les fichiers GeoJSON encodent les données géographiques des régions, et peuvent être facilement manipulés avec geopandas.
En cherchant "france geojson"sur Google, je suis tombé sur france-geojson, un repo maintenu par Grégoire David, que je remercie chaleureusement. Depuis ce repo, j'ai téléchargé departements-version-simplifiee.geojson en tant que france-geojson/departements-version-simplifiee.geojson.
Faites de même, puis importez geopandas pour lire ce fichier:
import geopandas as gpd
sf = gpd.read_file('france-geojson/departements-version-simplifiee.geojson')
sf.head()
Nous voyons que la géométrie de chaque département est stockée comme un polygone, avec la longitude et la latitude de chacun des points du polygone.
Il est facile de dessiner un département avec geopandas : il nous suffit de sélectionner une ligne dans la dataframe (ici la première pour le département de l'Ain), et d'évaluer la géométrie :
sf.loc[0].geometry
Nous allons maintenant tracer l'ensemble des départements, avec une couleur indiquant une valeur mesurée dans chaque département. Pour l'instant, nous n'avons pas encore de valeur à utiliser, donc nous en engendrons une aléatoirement :
import numpy as np
sf['value'] = np.random.randint(1, 10, sf.shape[0])
Regardons ce bout de code de plus près.
À droite, on utilise numpy pour engendrer un tableau d'entiers entre 1 et 10, de longeur égale au nombre de lignes dans la dataframe, c'est à dire sf.shape[0]. Ensuite, on assigne ce tableau à une nouvelle colonne dans la dataframe, appelée value.
Affichage de données géographiques avec geoviews¶
Dans le style de holoviews, il nous faut juste deux lignes pour afficher les départements. La première déclare le jeu de polygones à partir de notre dataframe geopandas. Nous choisissons explicitement le nom du département et la valeur comme "dimensions de valeur" (les dimensions correspondant à des valeurs mesurées, dépendant du département):
deps = gv.Polygons(sf, vdims=['nom','value'])
Ensuite, nous affichons les départements avec quelques options. La plus importante est color=dim('value'). Elle veut simplement dire que nous allons mapper value vers une échelle de couleurs linéaire pour chaque département. Et vous pouvez trouver une explication complète de ce que sont les objets dim dans la documentation de holoviews.
Veuillez noter que la colonne utilisée pour la couleur doit être dans vdims. J'oublie souvent!
from geoviews import dim
deps.opts(width=600, height=600, toolbar='above', color=dim('value'),
colorbar=True, tools=['hover'], aspect='equal')
Nous avons utilisé bokeh comme backend, et nous bénéficions donc des outils usuels de cette librairie (au dessus de la figure, comme je l'ai demandé). Vous pouvez essayer de zoomer avec la molette de votre souris, de déplacer la carte, et de survoler les départements pour obtenir des informations détaillées.
Créez une carte choroplèthe avec vos propres données¶
Dans l'exemple simple ci-dessus, nous avons défini aléatoirement une valeur pour chaque département. Mais en pratique, vous allez vouloir afficher des données qui ne sont pas présentes dans la dataframe geopandas. Nous avons donc besoin d'associer des données externes à cette dataframe avant affichage.
C'est ce que nous allons faire maintenant, en prenant comme exemple la population estimée dans chaque département en 2019. J'ai trouvé ces données ici au format xls, et les ai converties en fichier tsv (tab-separated values) pour créer le fichier population_france_departements_2019.tsv.
Pour lire ce fichier, nous utilisons pandas (dans sa version classique). Nous n'avons en effet pas besoin de geopandas ici car ce dataset ne contient aucune information géographique. Nous utilisons la méthode bien connue read_csv, en spécifiant que la tabulation est utilisée pour séparer les valeurs d'une ligne, et que la virgule indique les milliers. Vous pouvez simplement ouvrir ce fichier texte pour vous en assurer.
import pandas as pd
df = pd.read_csv('population_france_departements_2019.tsv', sep='\t', thousands=',')
df.head()
Après les premières colonnes qui indiquent le code et le nom de département, nous avons trois jeus de colonnes pour le nombre d'habitants du département. Les préfixes correspondent à:
t_: nombre totalh_: nombre d'hommesf_: nombre de femmes
Et dans chaque jeu, il y a une colonne par tranche d'âge.
Maintenant, nous devons associer les données de cette dataframe pandas (df) à notre dataframe geopandas (sf). C'est très facile avec la méthode merge.
Ci-dessous, on merge les données sur chaque ligne, en s'assurant que la valeur de la colonne codede sf est égale à la valeur de la colonne depcode de df. L'option suffixes concerne les colonnes ayant le même nom dans df et sf, comme nom. Cet option détermine le nom que les colonnes auront après le merge. Ici, je souhaite que la colonne qui vient de sf garde son nom, et que celle venant de df récupère un suffixe _y.
jf = sf.merge(df, left_on='code', right_on='depcode', suffixes=('','_y'))
jf.head(2)
Et nous pouvons maintenant afficher la population totale de chaque département. Nous ajoutons au passage le nombre d'hommes et le nombre de femmes aux tooltips, en ajoutant ces colonnes à vdims. De plus, veuillez noter que j'ai normalisé le nombre d'habitants pour l'afficher en millions.
# declare how the plot should be done
regions = gv.Polygons(jf, vdims=['nom', 't_total', 'h_total', 'f_total'])
regions.opts(width=600, height=600, toolbar='above', color=dim('t_total')/1e6,
colorbar=True, tools=['hover'], aspect='equal')
Conclusion
Dans cet article, vous avez appris:
- comment s'y retrouver dans les multiples outils de visualisation de python, et comment démarrer rapidement;
- comment créer vos premières cartes choroplèthes
- où trouver les définitions des frontières géographiques pour vos cartes
- à connecter vos propres données aux territoires, pour afficher ce que vous souhaitez.
- qu'il y a du monde, dans le Nord, en fait!
Si vous connaissez des ressources de données ouvertes pour la visualisation géographique, n'hésitez pas à nous les donner en commentaire!
N'hésitez pas à me donner votre avis dans les commentaires ! Je répondrai à toutes les questions.
Et si vous avez aimé cet article, vous pouvez souscrire à ma newsletter pour être prévenu lorsque j'en sortirai un nouveau. Pas plus d'un mail par semaine, promis!
Encore plus de data science et de machine learning !
Rejoignez ma mailing list pour plus de posts et du contenu exclusif: