Simple Text Mining with Pandas
Prepare the yelp dataset (shop reviews) for natural language processing.

Introduction
This is the start of a series of tutorials about natural language processing (NLP). In other words, we're going to teach the machine how to read! First, we'll see how to do simple text mining on the yelp dataset with pandas.
The yelp dataset contains over 6 million text reviews from users on businesses, as well as their rating. This dataset is interesting because it is large enough to train advanced machine learning models like LSTMs (Long Short-Term Memories). It is also large enough to be fairly challenging to process.
In this first post, you will learn how to:
- access and understand the yelp dataset
- convert it to a pandas DataFrame for simple text mining.
Prerequisites
- You need a computer with at least 2 GB of usable RAM.
- I assume you're using a unix-like system, e.g. Linux or mac OS. But all steps can be followed in Windows as well (though I don't know how to do that.)
- You should have Anaconda for python 3 installed.
The yelp dataset
First, download the yelp dataset . You will need to leave your name and email address, but this is completely free.
The dataset in 3.6 GB in compressed form, and 8.1 GB after unpacking. We want to read only one file from the dataset, of size 5 GB.
First, unpack the archive wherever you like:
mkdir yelp_dataset
cd yelp_dataset
tar -zxcf <path_to_the_archive>/yelp_dataset.tar.gz
Our dataset is in the file review.json. It is a 5GB file:
ls -l review.json
> -rw-r--r--@ 1 cbernet cms 5.0G Nov 15 17:35 review.json
First, we need to look in this file to understand what to do. We can count the number of lines, and see that there are almost 6.7 M lines:
wc review.json
> 6685900 747774944 5347475638 review.json
And we can look at the first line:
head -n 1 review.json
>
{"review_id":"Q1sbwvVQXV2734tPgoKj4Q","user_id":"hG7b0MtEbXx5QzbzE6C_VA","business_id":"ujmEBvifdJM6h6RLv4wQIg","stars":1.0,"useful":6,"funny":1,"cool":0,"text":"Total bill for this horrible service? Over $8Gs. These crooks actually had the nerve to charge us $69 for 3 pills. I checked online the pills can be had for 19 cents EACH! Avoid Hospital ERs at all costs.","date":"2013-05-07 04:34:36"}
This file is in the JSON Lines format, which means that each line is in the JSON format.
The "stars" field contains the notation, and the "text" field contains the review. In future posts, we will train our machine to predict whether a review is positive or negative given the review text.
The "stars" field will be used to define the label for each review, e.g. treating all reviews with stars > 3 as positive, and all the others as negative.
Some of the other fields certainly provide useful information as well. For example, the "useful" field provides credibility to a user review.
Now that we know what the dataset looks like, we would like to do a statistical analysis to learn more about this dataset. For example, here are a few questions you may have:
- how long is the review text?
- what is the distribution of stars
- are there correlations between variables? For example, are long reviews considered more useful than shorter ones?
To do that, we will load part of the dataset in memory and use pandas. But first ...
Know your limits
Before doing any large scale data analysis, you need to know how much resources are available on your computer. The resources we care about are:
- The amount of RAM (Random Access Memory). The data stored in the RAM is accessed directly by the processor.
- The amount of disk space . Disk space is necessary to store your samples.
- The number of cores in the processor . The more cores you have, the more processes you'll be able to run simultaneously
Typically, a notebook has at least 4 GB of RAM, 250 GB of disk, and two cores.
To find out how much you have, do the following.
Linux
# number of cores
cat /proc/cpuinfo
# RAM
free
# disk space
df -h .
Mac OS
# number of logical cores
sysctl -n hw.ncpu
# RAM
sysctl -h hw.memsize
# disk space
df -h .
Remember this information. If you exhaust your RAM, your computer will start swapping and get very slow. If you fill up your disk, you will start getting errors from system processes trying to write to the disk.

Reading JSON and loading the pandas DataFrame
Before you attempt to run the script below: In my case, the iteration over the lines in the file was failing with:
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 8145: ordinal not in range(128)
To fix this, I had to set this environment variable:
export LANG=en_US.UTF-8
It might not be necessary or advisable in your case, but please keep that in mind.
Without further ado, here is the full script I have written to process this dataset:
import json
import pandas as pd
import matplotlib.pyplot as plt
# open input file:
ifile = open('review.json')
# read the first 100k entries
# set to -1 to process everything
stop = 100000
all_data = list()
for i, line in enumerate(ifile):
if i%10000==0:
print(i)
if i==stop:
break
# convert the json on this line to a dict
data = json.loads(line)
# extract what we want
text = data['text']
stars = data['stars']
# add to the data collected so far
all_data.append([stars, text])
# create the DataFrame
df = pd.DataFrame(all_data, columns=['stars','text'])
print(df)
# df.to_hdf('revie20ws.h5','reviews')
ifile.close()
To run this script interactively, start ipython in pylab mode, from the yelp_dataset directory:
ipython --pylab
and within the ipython prompt do
%run the_script.py
Using the pandas DataFrame
My goal is not to teach you pandas here, as there are excellent tutorials around. Instead, I would like to show you how powerful and fast it is.
In ipython, after running the script, we have interactive access to our DataFrame object, called df.
Let's start by looking at the possible values for stars:
stars = df['stars']
sorted(stars.unique())
# [1.0, 2.0, 3.0, 4.0, 5.0]
Now we can plot the distribution of stars in an histogram:
plt.hist(stars, range=(0.5, 5.5), bins=5)
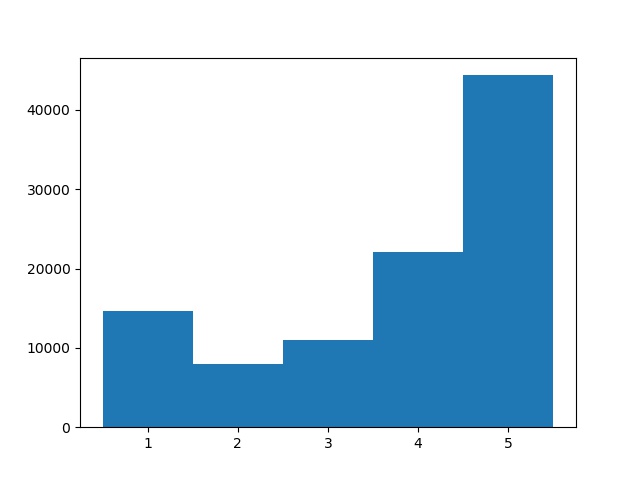
People are actually kind! I'm not the only one to only give good reviews.
Now let's have a look at the review text size:
plt.clf() # clear previous figure
plt.hist(df['text'].str.len(), bins=100)
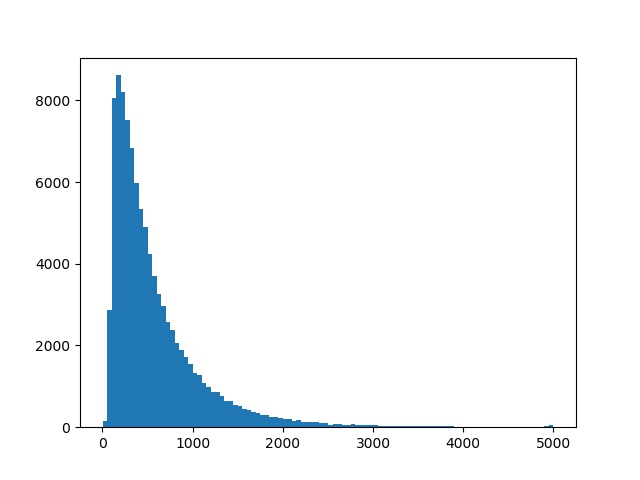
Wow... a few reviewers felt the need to write 5000 characters about a business... Let's find the entrie(s) with maximum text length and have a look.
df.loc[ df['text'].str.len() == df['text'].str.len().max() ]
stars text
31846 1.0 This place is awful. If quick and dirty brunch...
39095 1.0 My husband and I were so overly disappointed i...
78683 4.0 My review will focus on the Arizona State Fair...
print( df.loc[31846].text )
I'll save you the text here, but this was not a happy customer :-)
Conclusion
As an exercise, you can try to repeat the exercise, processing all lines in the review.json file. You need at least 16GB of RAM to do that.
If you don't have that much RAM, don't do it , and don't worry. In the next post, we'll see how to process this dataset in a less memory-intensive way.
In this post, you have learnt how to:
- find out about the RAM, CPU cores, and disk space resources on your computer;
- read a JSON Lines file;
- fill a pandas DataFrame with the information in this file;
- use pandas to investigate about the dataset.
Our next step will be to convert the yelp dataset to a form usable in machine learning.
Please let me know what you think in the comments! I’ll try and answer all questions.
And if you liked this article, you can subscribe to my mailing list to be notified of new posts (no more than one mail per week I promise.)
Learn about Data Science and Machine Learning!
You can join my mailing list for new posts and exclusive content: